Prerequisites
Ensure that you have first read the README file.
Introduction
What DiffKit is
DiffKit is an application for comparing two tables of data, field-by-field. DiffKit is able to report the differences (Diffs) at both the row and field level, and allows the user to configure how to carry out the comparison (what to compare, what to ignore). DiffKit is highly configurable with respect to the sources of tabular data, the details of the comparison, and the characteristics of the diff report (output). For instance, DiffKit is able to diff MS Excel files, RDBMS tables, CSV files, or custom data sources, in any combination.
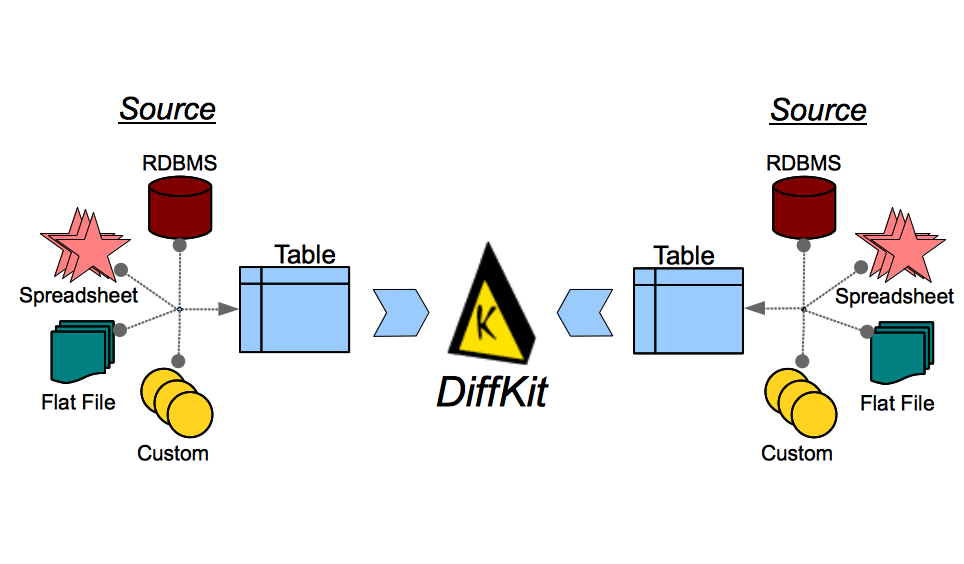
DiffKit is able to compare fields within a prescribed tolerance (e.g. numeric field values will be flagged as different only if the difference exceeds some threshold), is able to diff text fields ignoring incidental formatting differences, and is able to output the diffs as a structured text report or as SQL insert statements. This is just a small sampling of the capabilities of DiffKit.
DiffKit is also a framework. It is Free Open Source Software (FOSS). DiffKit is written in the Java programming language and is dependent on only the Java Runtime Environment (JRE) and a handful of third party FOSS libraries that are packaged as part of the DiffKit distribution. As an Open Source framework with few dependencies, DiffKit can be easily and cleanly embedded in almost any Java application, or any application that can bind Java packages.
DiffKit was designed to be easily extensible. That means it requires only a very modest java programming effort to create custom row data providers (Sources), custom field comparators (Diffors), and custom output formatters (Sinks).
DiffKit is a command-line application that is configured entirely by XML files. Because there is no GUI, and because it’s file driven, and because it runs on Java, DiffKit is able to execute in a huge range of computing environments-- Windows and Mac desktops, or Linux and Solaris servers. These characteristics also make DiffKit ideal for scripting or embedding into process chains. Also, DiffKit was designed with high-volume applications in mind. It uses a row-streaming mechanism to maintain a very low memory overhead during diff execution, so DiffKit is able to quickly and efficiently diff tables that have tens of millions of rows.
What DiffKit is not
DiffKit is not a visual comparison tool; it does not have a GUI. DiffKit is not
a code or unstructured text comparison tool-- it is designed to compare tables
(data that is arranged in rows and columns). If you want to compare unstructured
text, you should use Unix diffutils
[http://www.gnu.org/software/diffutils/.]
. DiffKit is not a
synchronization tool. DiffKit has no capabilities to patch one side to make it
look like the other side; i.e. it can only report differences, not act on them.
DiffKit is not an RDBMS schema synchronization tool. There are many products on
the market that already do this. While you can use DiffKit to diff RDBMS
schemas, you will have to supply the configuration files yourself-- out of the
box DiffKit does not know how to identify the schema or catalog tables for any
particular vendor product. Finally, DiffKit is not very helpful for diff’ng
binary files. The diff reporting mechanism is oriented towards data types that
can be displayed as text.
Why use DiffKit?
There are many uses for DiffKit, a couple of which are explored in detail in Motivations and Uses. Briefly, DiffKit is an excellent application for enterprise data regression. It’s quite common that enterprise systems have complex workflows that produce large or complex RDBMS data output. By diff’ng newly produced table values against expected table values, you can ensure that you do not experience unanticipated changes to output as a result of changes to the process. Likewise, most enterprise development environments rely on different databases for different stages in the SDLC. It can become difficult to keep the database objects in synch across these different environments. DiffKit can diff the schemas to report on differences amongst the same database objects across different environments.
There are many reasons to use DiffKit rather than other products. DiffKit is free and open source. Also, as far as I know, there are no products on the market, commercial or free, that are designed for high-performance, high-volume, enterprise data diff’ng. Also, DiffKit is command-line driven, so it is conveniently scriptable and embeddable into workflows. DiffKit has a clean, simple, Object Oriented Design that makes it easy for Java programmers to extend. Finally, DiffKit is a high quality product, undergoing continuous testing to ensure the accuracy of its results.
Quality control
The integrity of DiffKit is maintained via two levels of testing: unit testing, and high level functional regression testing. The DiffKit project contains 160+ low-level unit tests. These tests are executed before each release. But more importantly, the DiffKit standalone application carries with it a complete, high-level functional regression suite. Not only is this test suite exercised before every release but, because it is embedded in the standalone application, end-users are able to execute this test suite at any time. For a detailed description of this test suite, read Test Cases.
Tutorial
Tutorial 1 — Diff’ng flat-file tables
In this tutorial we will diff two CSV files. Like most diff utilities, DiffKit arbitrarily names one of the tables (files) the Left Hand Side (LHS) and the other table (file) the Right Hand Side (RHS). In order to carry out a diff, DiffKit must be configured with the location of the LHS and RHS tables, the characteristics of the comparison, and a description of the desired output. All of this information is specified in a Plan file. A Plan file is an XML configuration file (for enterprise Java programmers, it’s a Spring bean configuration file). There are two kinds of plans: MagicPlan and PassthroughPlan. In this example we will use a MagicPlan.
This plan is called Magic because it infers a lot of information, rather than requiring the user to fully specify every last detail of how the comparison should be carried out. The goal of the magic plan is to allow the user to specify the bare minimum amount of information required to accurately perform the diff.
In this example, that bare minimum of information is: the LHS file name, the RHS file name, and the name of a file to send the output to. Information that is not specified here, which the MagicPlan will infer, includes: which columns should be diff’d, what key should be used to match each row from the LHS to a row on the RHS, how to map columns on the left to columns on the right, and what type of comparison (which Diffor) to apply at each LHS-column-to-RHS-column mapping. In the case of the MagicPlan, the convenient default specifications that the MagicPlan provides are: all columns that appear on both the LHS and RHS will be diffed, other columns are ignored; the first column on each side is designated the key (analogous to a SQL key), used to join the rows; each column on the LHS will be mapped to the column on the RHS having the same name; an exact textual comparison will be performed (DKEqualsDiffor will be applied).
After you have unzipped the DiffKit distribution (diffkit-<version>.zip), you should see these files and directories:
conf/ diffkit-app.jar doc/ eg/
diffkit-app.jar is the standalone java application. It is completely self-contained, and can be run this way:
java -jar diffkit-app.jar
All of the data and configuration files needed for this tutorial are in the eg/ directory:
cd eg/
All of the files in this directory come from the DiffKit builtin Test Case suite. In this tutorial, we will start by invoking the same diff that TestCase9 invokes. It utilizes these files:
test9.lhs.csv test9.rhs.csv test9.plan.xml
We want DiffKit to compare the data table in test9.lhs.csv with that in test9.rhs.csv. The plan for this is almost as simple as a plan can get:
<beans ...>
<bean id="plan" class="org.diffkit.diff.conf.DKMagicPlan">
<property name="lhsFilePath" value="./test9.lhs.csv" />
<property name="rhsFilePath" value="./test9.rhs.csv" />
<property name="sinkFilePath" value="./test9.sink.diff" />
</bean>
</beans>
This file shows that we are using a MagicPlan (instead of a PassthroughPlan) and where to find the LHS and RHS csv files. It also specifies where the Sink should write its output file. A Sink is where diffs are sent to for formatting. We can run the diff this way:
java -jar ../diffkit-app.jar -planfiles test9.plan.xml
DiffKit prints a summary of the results to the console:
diff'd 8 rows in 0:00:00.009, found: !4 row diffs @2 column diffs
The summary tells us that there were 4 row diffs; a row diff occurs when DiffKit finds a row on one side, but no corresponding row on the other side. Rows are uniquely identified by a key (analogous to a primary key in relational DBs) which defaults to column1 if not otherwise specified. The summary states that there were also 2 column diffs, which means that DiffKit was able to join (align) the rows, but that values in some of the columns were different between the left and right hand side.
Running test9.plan.xml above created an output (diff) file named test9.sink.diff. That file contains an entry for each diff discovered. The first entry in that file describes a column diff:
@{column1=1111}
column2
<1111
>xxxx
It tells us that the row identified by the key value (column1=1111) has a column diff in column2. The lhs value for column2 is 1111 while the rhs value is xxxx. The next entry in the diff file describes a row diff:
!{column1=2222}
<
This indicates that the row identified by column1=2222 is missing from the lhs. Or put another way, this row is present on the rhs and not present on the lhs. You should open test9.lhs.csv side-by-side with test9.rhs.csv in order to verify that all entries in the diff file match your expectations.
test11.plan.xml shows how to explicitly specify which columns constitute the key, used to align (join) the rows between lhs and rhs:
...
<property name="keyColumnNames">
<list>
<value>column3</value>
...
test13.plan.xml demonstrates how to instruct DiffKit to consider only certain columns during comparison, ignoring all other columns:
...
<property name="diffColumnNames">
<list>
<value>column2</value>
...
It also shows how to specify that rows should be identified in the output (diff) file by values other than the key values:
...
<property name="displayColumnNames">
<list>
<value>column1</value>
<value>column3</value>
...
test14.plan.xml demonstrates how to tell DiffKit to consider all columns during comparison except for a specified list (blacklist).
...
<property name="ignoreColumnNames">
<list>
<value>column3</value>
<value>column4</value>
...
test21.plan.xml shows how to specify which kinds of diffs should be considered: ROW_DIFF, COLUMN_DIFF, or BOTH (default). It also shows how to tell DiffKit to halt diffing after a certain number of diffs has been recorded:
... <property name="diffKind" value="ROW_DIFF" /> <property name="maxDiffs" value="2" /> ...
Tutorial 2 — Diff’ng database tables
|
Note
|
You should complete Tutorial 1 before starting on this tutorial. Tutorial 1 introduces terminology that is used here. |
In this tutorial we will diff two RDBMS database tables. Diff’ng DB tables uses plan files in the same fashion as diff’ng files. But instead of file paths, you must provide table names in the plan file, and you must also tell DiffKit how to connect to the LHS and RHS databases.
The DiffKit standalone application (diffkit-app.jar) carries with it a fully
functional embedded SQL database: H2
[http://www.h2database.com/.]
. The
storage for the tutorial H2 database is in a single file: eg/demo.h2.db.
Appropriate database tables have been created in demo.h2.db and prepopulated
with all of the data in files test10.lhs.csv and test10.rhs.csv. The CSV files
are here simply as a convenience, to allow you to see the test data without
having to open a database browser. If you would like to directly view the H2
tables and data, you need a DB browser that can use a type 4 JDBC driver to
connect to a database. DiffKit can run the embedded H2 DB as a tcp server from
the eg/ directory, allowing you to connect from an external DB browser:
java -jar ../diffkit-app.jar -demoDB
Then configure a connection to this demo database within your favorite JDBC enabled database browser:
driver name: H2 JDBC Driver driver class name: org.h2.Driver driver jar: h2-1.2.135.jar (you can unzip diffkit-app.jar to get a copy) connection URL: jdbc:h2:<absolute path of eg/ directory>/demo database name: demo username: test password: test
Your DB browser will show you the tables TEST10_LHS_TABLE and TEST10_RHS_TABLE (amongst others) populated with the data values from the corresponding CSV files.
test10.plan.xml demonstrates how to specify the table names used in the comparison:
... <property name="lhsDBTableName" value="TEST10_LHS_TABLE" /> <property name="rhsDBTableName" value="TEST10_RHS_TABLE" /> <property name="dbConnectionInfo" ref="connectionInfo" /> ...
In this case, both tables reside in the same database, referenced by "connectionInfo". Of course we also have to provide values for connectionInfo. We could put the connectionInfo element for these tables in the test10.plan.xml file, and then all information needed for the diff would be in one config file. Instead, we isolate the database connectionInfo values into a separate file:
...
<bean id="connectionInfo" class="org.diffkit.db.DKDBConnectionInfo">
<constructor-arg index="0" value="test" />
<constructor-arg index="1" value="H2" />
<constructor-arg index="2" value="file:./demo" />
<constructor-arg index="3">
<null />
</constructor-arg>
<constructor-arg index="4">
<null />
</constructor-arg>
<constructor-arg index="5" value="test" />
<constructor-arg index="6" value="test" />
</bean>
This allows us to reuse the connectionInfo in other plans as well. The connectionInfo points to an embedded H2 database named "test", which is stored in a file at "./demo" (i.e. eg/demo.h2.db). The username is "test" and the password is "test". An embedded H2 database will run in the same process as DiffKit itself-- you do not need to run the diffkit-app.jar demoDB. To run the test10 plan:
java -jar ../diffkit-app.jar -planfiles test10.plan.xml,dbConnectionInfo.xml
Test10 shows that DiffKit allows the user to specify what key should be used to join (align) the rows, even if a different SQL primary key (PK) is already defined within the database:
...
<property name="keyColumnNames">
<list>
<value>COLUMN3</value>
...
In this particular case, the PK defined in the database for both tables is column1. If DiffKit had used column1 as its key, then all rows would have appeared as row diffs, because no rows join. Instead, we specified that the key is column3, in which case all rows join and there are no row diffs.
DiffKit can compare tables across different physical and/or logical databases. test18.plan.xml demonstrates this:
...
<bean id="connectionInfo" class="org.diffkit.diff.conf.DKMagicPlan">
<property name="lhsDBTableName" value="TEST18_LHS_TABLE" />
<property name="rhsDBTableName" value="TEST18_RHS_TABLE" />
<property name="lhsDBConnectionInfo" ref="lhsDBConnectionInfo" />
<property name="rhsDBConnectionInfo" ref="rhsDBConnectionInfo" />
...
</bean>
In this case, table "TEST18_LHS_TABLE" is located in a database pointed to by ref="lhsDBConnectionInfo" while table "TEST18_RHS_TABLE" is located in a database pointed to by ref="lhsDBConnectionInfo". Again, as in test10, the values for the references to lhsDBConnectionInfo and rhsDBConnectionInfo are in a separate file. However, in this case, lhsDBConnectionInfo and rhsDBConnectionInfo are each in their own file: test18.rhs.dbConnectionInfo.xml and test18.lhs.dbConnectionInfo.xml respectively. Inside, we can see that each of these dbConnectionInfo.xml files specifies a connection to a different database:
...
<bean id="lhsDBConnectionInfo" class="org.diffkit.db.DKDBConnectionInfo">
...
<constructor-arg index="2" value="file:./test18_lhs_demo" />
...
...
<bean id="rhsDBConnectionInfo" class="org.diffkit.db.DKDBConnectionInfo">
...
<constructor-arg index="2" value="file:./test18_rhs_demo" />
...
Then the plan can be executed this way:
java -jar ../diffkit-app.jar -planfiles test18.plan.xml,
test18.lhs.dbConnectionInfo.xml,test18.rhs.dbConnectionInfo.xml
DiffKit can also compare a file table with a DB table:
... <property name="lhsDBTableName" value="TEST12_LHS_TABLE" /> <property name="rhsFilePath" value="./test12.rhs.csv" /> <property name="dbConnectionInfo" ref="connectionInfo" /> ...
In this case, you should put the DB table on the LHS, if you want to ensure that DiffKit creates a TableModel from the DB table and applies that same TableModel to the file table as well.
Test12 can be run this way:
java -jar ../diffkit-app.jar -planfiles test12.plan.xml,dbConnectionInfo.xml
Tutorial 3 — Diff’ng spreadsheet tables
|
Note
|
You should complete Tutorial 2 before starting on this tutorial. Tutorial 2 introduces terminology that is used here. |
In this tutorial we will diff two Excel spreadsheet tables (sheets). Diff’ng spreadsheet tables uses plan files in the same fashion as diff’ng flat-files or DB tables. But instead of DB connection info, you must provide the path to the spreadsheet file and the name of the sheet to use.
test33.plan.xml demonstrates how to specify the table names used in the comparison:
... <property name="lhsSpreadSheetFilePath" value="./test33.lhs.xls" /> <property name="rhsSpreadSheetFilePath" value="./test33.rhs.xls" /> <property name="hasHeader" value="true" /> <property name="sinkFilePath" value="./test33.sink.diff" /> ...
We don’t specify the sheet name anywhere, so DiffKit will default to using the first sheet in the workbook, which in this case happens to be named "Sheet1" (the same in both documents). Also notice that hasHeader is set to "true". That means DiffKit will use the first row (ROW_NUM =1) as the column name for each column. The output report will explain diffs using these column names instead of the default Excel column names: A,B…AA,AB…. Finally, we did not specify the key anywhere, which means that DiffKit will use the ROW_NUM as the key for the sake of aligning the rows. Test34 (test34.plan.xml) demonstrates the results of diff’ng spreadsheets that are nearly identical to those in test33, but using one of the user columns (COLUMN1) as the key instead of ROW_NUM:
...
<property name="lhsSpreadSheetFilePath" value="./test34.lhs.xls" />
<property name="rhsSpreadSheetFilePath" value="./test34.rhs.xls" />
<property name="hasHeader" value="true" />
<property name="isSorted" value="false" />
<property name="keyColumnNames">
<list>
<value>COLUMN1</value>
</list>
</property>
...
The results are completely different from those in Test33 because of the different row alignments provided by the different keys. Notice that we also specified isSorted = false. By default, DiffKit assumes that spreadsheets already have the row ordering that you want; in other words, isSorted defaults to true. That default row ordering is according to the native ROW_NUM that all spreadsheets provide. However, you can instruct DiffKit to override this default row ordering with the isSorted = false flag. In that case, DiffKit will itself sort the rows according to the keyColumnNames before performing the table comparisons.
Tutorial 4 — PassthroughPlan
|
Note
|
You should complete Tutorial 2 before starting this tutorial. Tutorial 2 introduces terminology that is used here. |
Tutorials 1, 2 and 3 used MagicPlans. These plans are called "magic" because not all of the information needed to carry out the diff’ng is explicitly specified; most of it is inferred, using reasonable default assumptions. However, sometimes you need finer control over the specification than is possible with MagicPlan. In that case, you will need to use a PassthroughPlan.
At the heart of DiffKit is the DiffEngine. In order for the DiffEngine to carry out a diff’ng, it must be given a complete specification of how to compare the two tables. This specification is an element called the TableComparison (Fig. 2). For an explanation of TableComparisons, see Concepts. Configuring a PassthroughPlan mostly concerns building a TableComparison in the config file.
test7.plan.xml demonstrates how to build up a PassthroughPlan. You can see that, unlike the previous tutorials, the plan "class" is PassthroughPlan, not MagicPlan:
...
<bean id="plan" class="org.diffkit.diff.conf.DKPassthroughPlan">
...
<property name="tableComparison" ref="table.comparison" />
...
And you also see above that a "tableComparison" is explicitly specified, unlike in the case of the MagicPlan. Next we see how the tableComparison is composed from primitive elements. First, each column must be explicitly modelled with a ColumnModel element:
...
<bean id="lhs.column1" class="org.diffkit.diff.engine.DKColumnModel">
<constructor-arg index="0" value="0" />
<constructor-arg index="1" value="column1" />
<constructor-arg index="2" value="STRING" />
</bean>
...
Next, the ColumnModels are composed into TableModels:
...
<bean id="lhs.table.model" class="org.diffkit.diff.engine.DKTableModel">
<constructor-arg index="0">
<list>
<ref bean="lhs.column1" />
<ref bean="lhs.column2" />
<ref bean="lhs.column3" />
</list>
...
...
The TableModel specification includes not just the list of ColumnModels, but also the list of column indexes that make up the Key:
...
<constructor-arg index="1">
<list>
<value>0</value>
<value>2</value>
</list>
...
Next, you have to include in the specification which Diffor to use for each ColumnComparison. Here we are going to just use the same generic EqualsDiffor for all ColumnComparisons:
...
<bean id="equalsDiffor" class="org.diffkit.diff.diffor.DKEqualsDiffor"
factory-method="getInstance" />
...
For each column pair that we want diff’d, we need to create a ColumnComparison, which specifies the identity of the LHS column (ColumnModel), the RHS column, and the Diffor to apply to these column values:
...
<bean id="column1.comparison" class="org.diffkit.diff.engine.DKColumnComparison">
<constructor-arg index="0" ref="lhs.column1" />
<constructor-arg index="1" ref="rhs.column1" />
<constructor-arg index="2" ref="equalsDiffor" />
</bean>
...
Finally, the above elements are composed into a TableComparison:
...
<bean id="table.comparison" class="org.diffkit.diff.engine.DKStandardTableComparison">
<constructor-arg index="0" ref="lhs.table.model" />
<constructor-arg index="1" ref="rhs.table.model" />
<constructor-arg index="2" value="BOTH" />
<constructor-arg index="3">
<list>
<ref bean="column1.comparison" />
<ref bean="column2.comparison" />
<ref bean="column3.comparison" />
</list>
</constructor-arg>
<constructor-arg index="4">
<list>
<value>1</value>
</list>
</constructor-arg>
<constructor-arg index="5">
<list>
<list>
<value>0</value>
<value>2</value>
</list>
<list>
<value>0</value>
<value>2</value>
</list>
</list>
</constructor-arg>
<constructor-arg index="6" value="2" />
</bean>
...
The elements nested in the TableComparison specify: LHS and RHS TableModels (index=0,index=1); the Kind of Diffs to looks for, ROW_DIFF, COLUMN_DIFF, or BOTH (index=2); a list of ColumnComparisons (index=3); a list of indexes (into the list of ColumnComparisons) of which ColumnComparisons should actually participate in the diff’ng (index=4); a list of indexes (into the respective TableModel column lists), one for the LHS and one for the RHS, of which columns to use for identifying rows in the output (index=5); and the maximum number of diffs to record before stopping (index=6).
Test7 can be run with this command:
java -jar ../diffkit-app.jar -planfiles test7.plan.xml
Motivations and Uses
Data Regression testing
Today, complex software workflows that output large amounts of data into an RDBMS are fairly common. Most in-production enterprise software systems require continuous maintenance, upgrade, enhancement, refinement, and migration. But with each and every change to these systems, the maintainers must ensure that only their intended changes are realized, and that there are no unintended changes as side-effects. This concern is usually addressed through regression testing.
In theory, regression testing processes that output data is fairly simple. You start with a fixed, predefined, set of inputs, and run these inputs through the process before changes to the process are applied. You then apply your process changes and run the changed process with the same set of inputs as the previous step. You then compare the outputs from the first step with the outputs from the second step. They should be identical, or reflect only intended changes to the process.
In practice, performing data regression on large, complex, RDBMS data sets is quite challenging. Frequently, the exact same process run twice will not produce exactly the same output. There will be data values that are senstive to when the process was run (timestamps), and who ran the process (user ids). It’s not uncommon for some processes to produce some data values that are somewhat non-deterministic (random). Also, if the data sets are large (millions of very wide rows), performance of the diff’ng tools can become a roadblock. Comparing large byte volumes requires tools that are very efficient in their use of resources.
DiffKit is designed specifically for enterprise diff’ng (although it is still quite suitable for smaller scale projects).
- Performance
-
DiffKit is designed to operate on large datasets-- tens of millions of rows. The DiffEngine will only ever hold 2 rows in memory at the same time. It does not require that whole datasets, or even chunks, be present in memory (Java heap) concurrently. As a result, DiffKit maintains a very small memory footprint at all times. Further, DiffKit is fairly fast.
- Command line
-
DiffKit is strictly command-line driven-- it has no GUI. As a result, DiffKit can run on headless servers, as well as desktops. DiffKit is fully configured from files passed on the command-line, and does not require any complicated database backing for configuration. And DiffKit can send its output (diffs) to file as well. So DiffKit can be called from shell scripts, and easily embedded in process chains. DiffKit can be configured to exit with an error status code if diffs are detected. And since DiffKit is an open Java framework, it can be easily embedded into any Java application.
- Customization
-
DiffKit is highly customizable. Configuration allows the user to include or ignore only certain rows/columns, to focus on only row or column type diffs, and to stop diff’ng after some diff count has been reached. Also, DiffKit can use a set of out-of-the-box Diffors (comparators) to achieve sophisticated diff’ng tolerance, where anticipated or non-erroneous diffs can be ignored. Finally, with a little Java programming, you can plug in Diffors that you write yourself, allowing limitless expression of diff and tolerance behavior.
DB schema comparison
It’s quite common in enterprise software development to maintain a chain of host environments (logically independent machines), each of which represents a different stage in the Sofware Development Life Cycle (SDLC). Typically, a development team will maintain, at a bare minimum: Dev→QA→Prod. It’s not uncommon to see more elaborate chains, such as: Dev→Integration→QA→User Acceptance→Performance→Dev. If the target application uses a SQL database for storage, it’s quite likely that the schema (DDL) of that database is continually evolving as other components of the system change. Then, a vital issue becomes; how to ensure that the database objects (DDL) are "in synch" across all of these different, and evolving, environments.
All mainstream RDBMS databases maintain their schema (or catalog) in a special set of sytems tables, called the system catalog views. With the proper plan (configuration) files, DiffKit can detect and report differences between database object definitions across different physical databases.
Concepts
Real world entities
DiffKit is designed to compare tables of data. These could come from an RDBMS table, a CSV file, an Excel spreadsheet, or any other data that can be represented in a table. In this context, table presumes a rectangular array of values, where all of the values in the same column represent the same data element; that is, values in the same column have the same meaning and same data type. Rows represent different instances of the collection of column values. Conceptually, data table means the same thing as a SQL table, however it can come from any type of source.
Modelling entities
In order to provide the most flexibility, DiffKit internally creates a meta model of each entity involved in the diff operation (Figure 2). So DiffKit will create a meta model of both the LHS source and the RHS source; the centerpiece of those models are the TableModels. It will also create meta classes to represent how each column on the LHS is mapped to a column on the RHS, and what Diffor to use for determining whether values in that column are different or the same. All of the underlined entities in Figure 2 are Java classes, and are individually addressable and configurable through the use of a PassthroughPlan
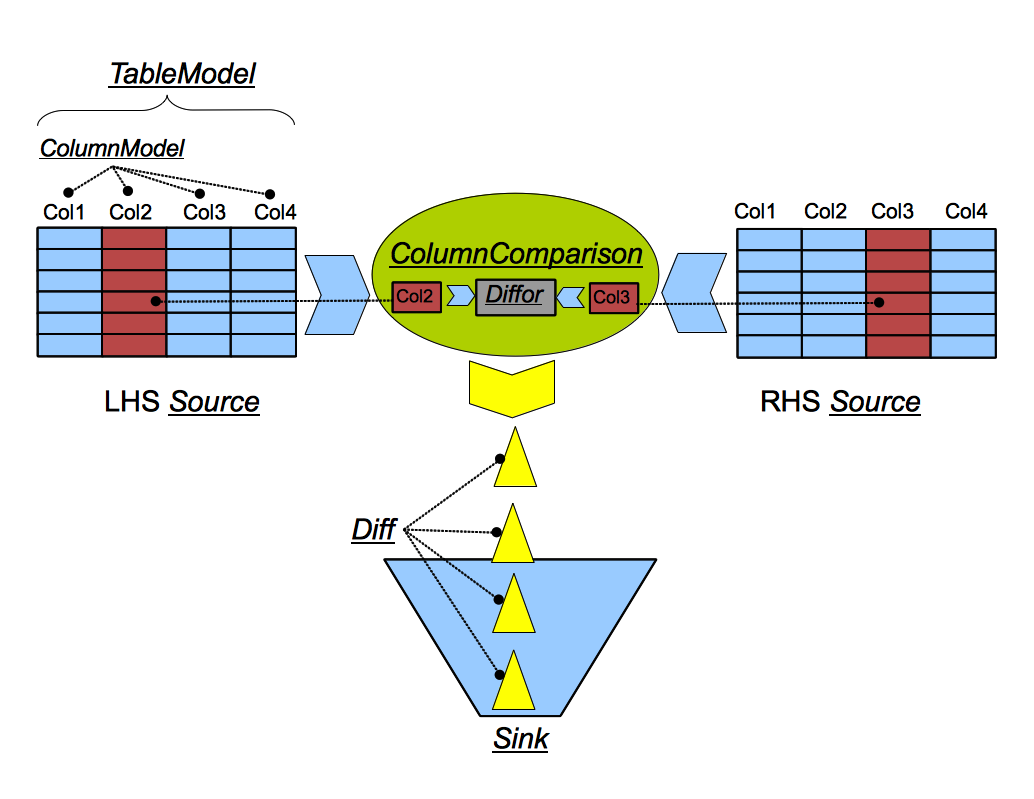
TableModel
The TableModel is a meta model describing all important aspects of a table involved in the DiffKit invocation. What are the characteristics and placements of each column, and what is the Key used to align (join) its rows to another table. The TableModel contains a ColumnModel for each column that it models. TableModel is a Java class.
ColumnModel
A ColumnModel is a meta model describing all important properties of a column involved in the diff. These properties include the name, datatype, and formatting defaults. ColumnModel is a Java class.
Source
A Source is a place from which DiffKit will read data rows for diff’ng. Every DiffKit invocation must specify a LHS and a RHS Source. Each Source is fully meta modelled by a TableModel. DiffKit comes with built-in Sources for RDBMS databases and CSV files. Java programmers can easily build their own Sources by implementing the java Source interface (Custom Source).
Sink
A Sink is an output destination for Diffs. The DiffEngine reads rows from the LHS and RHS Sources, detects Diffs, and sends the Diffs to a Sink. The Sink, depending on its type, will perform any of these tasks: format the Diffs, store the Diffs, display the Diffs, aggregate Diff statistics. Out-of-the-box DiffKit comes with a DBSink, which stores Diffs in a SQL DB, and a FileSink, which formats Diffs and writes the formatted strings to a specified text file. Java programmers can easily build their own Sources by implementing the java Sink interface (Custom Sink).
Row Alignment
In order to compare rows from the LHS with those from the RHS, DiffKit must have a basis for joining the two. For that, it uses a Key (Figure 3). A Key is a collection of RHS to LHS column associations. Conceptually, it’s the same as SQL Primary and Foreign keys. In Figure 3, the key comprises: LHS col1 maps to RHS col1, and LHS col2 maps to RHS col2. DiffKit allows any number or type of columns to participate in the key.
Plan
Every DiffKit invocation is carried out according to a Plan. This specifies everything that DiffKit needs in order to do its job: the identity of the LHS and RHS Sources, the identity and configuration of the Sink, and the TableComparison, which is a description of how to join the LHS to the RHS rows, and how to compare a column on the LHS with a column on the RHS (Figure 3). There are two types of Plans: MagicPlan and PassthroughPlan. Plans are fed to DiffKit via a set of XML config files (Spring config files). Or Plans can be built programmatically, if you are using DiffKit as a framework. Plan is a Java interface.
TableComparison
The TableComparison fully specifies how the DiffEngine can carry out the entire diff’ng operation. It maps LHS columns to RHS columns via ColumnComparisons. It describes how to join rows on the LHS with rows on the RHS. It can instruct the DiffEngine to stop diff’ng after a certain number of Diffs have been detected, or to search for only one (ROW_DIFF) or the other (COLUMN_DIFF) type of Diff. TableComparison is a Java interface.
ColumnComparison
ColumnComparison fully specifies how to carry out the comparison of one column on the LHS to cone column on the RHS. It points to one ColumnModel on each side and specifies which Diffor should apply. ColumnComparison is a Java class.
Diffor
A Diffor is an operator that examines a single LHS column value against a single RHS column value to determine if they are different or the same. DiffKit comes with several built-in Diffors that provide great flexibility in what kinds of differences are ignored (tolerance). Java programmers can easily build their own Diffors by implementing the java Diffor interface (Custom Diffor).
MagicPlan
The MagicPlan is one type of concrete plan that can be used to specify a plan. The goal of the MagicPlan is to minimize the amount of information the user must provide, as opposed to the PassthroughPlan, which requires the user to explicitly provide every detailed aspect of information that is needed to carry out the operation. MagicPlan will make reasonable assumptions about specification that was not provided by the user. For instance, MagicPlan will build ColumnComparisons by always matching a column on the LHS to the column on the RHS that has the same column name. If a column name only appears on one side or the other (can’t be matched), then MagicPlan will not build a ColumnComparison for it and it will not participate in the diff’ng. MagicPlan is a Java class that implements the Plan interface.
PassthroughPlan
The PassthroughPlan is one type of concrete plan that can be used to specify a plan. The goal of the PassthroughPlan is to maximize the amount of control that the user has over the diff’ng specification. So the PassthroughPlan requires the user to explicitly build a ColumnComparison for every column pairing that should participate in the diff’ng. PassthroughPlan allows the user, for instance, to map columns on one side to columns on the other side that do not have the same name or data type. It also allows users to specify any arbitrary Diffor, including potentially a custom Diffor, for every ColumnComparison in the specification.
Diff
A Diff is a record of a difference between a LHS data value a RHS data value. Diffs come in two flavors: ROW_DIFF and COLUMN_DIFF. Figure 3 shows a default TableComparison between two sources of rows, and the resulting Diffs; there are 2 ROW_DIFFs and 3 COLUMN_DIFFs.
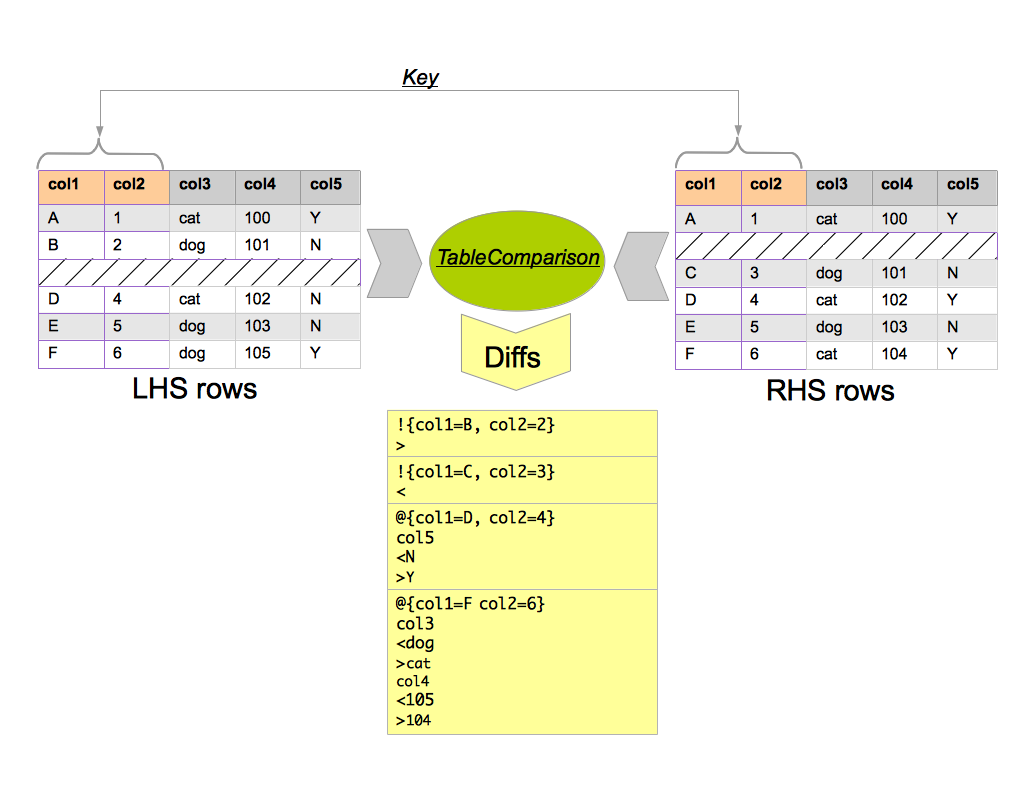
ROW_DIFF
A ROW_DIFF is a record that a row (as identified by the join Key) is present on one side, but not present on the other side. ROW_DIFFs are rows that could not be joined according to the join Key. In Figure 3, there are two ROW_DIFFs: the row identified by {col1=B, col2=2} is missing from the RHS, and the row identified by {col1=C, col2=3} is missing from the LHS.
COLUMN_DIFF
A COLUMN_DIFF is a record that a column value in a joined row is different (according to the Diffor in use) between the LHS and the RHS. In Figure 3. there are 3 COLUMN_DIFFs. The row identified by {col1=D, col2=4} has a N on the LHS for col5, but a Y on the RHS. The row identified by {col1=F, col2=6} has 2 COLUMN_DIFFs in it: one diff in col3 and one diff in col4.
Extending Diffkit
Custom Source — ArchiveSource
Coming soon.
Custom Diffor — ?
Coming soon.
Custom Sink — XMLSink
Coming soon.
Putting it together
Coming soon.
Test Cases
The test suite comprises TestCases. Each TestCase tests a particular scenario which is specified in a configuration file. The TestCase includes inputs, both left hand side (LHS) and right hand side (RHS), comparison configuration, and expected output. The TestCaseRunner will diff the LHS vs. the RHS and compare the actual results with the expected (known good) results. If the actual results do not match the expected results, the TestCase fails. DiffKit embeds a fully functional H2 database in order to carry out RDBMS based comparison. Each TestCase is fully documented. If you run the tests from the standalone application, you can inspect the resulting "tcr" directory and there you will find the input files, expected diff files and documentation (README) for each TestCase.